
CMU15445实验和学习笔记
课程主页:https://15445.courses.cs.cmu.edu/fall2022/schedule.html
调试
因为在线测评的样例是不公开的,而本地样例非常简陋,经常出现本地满分通过,在线平台只有六七十分的情况,为了debug,我们可以在每个函数内加上下面这样的语句,这样就可以在测评平台的log中输出调用的函数顺序和参数信息
char loginfo[200];
snprintf(loginfo, sizeof(loginfo), "echo record access frame_id: %d", frame_id);
system(loginfo);
在明确测评平台的测评文件后,我们也可以直接使用
system("cat /autograder/../../filename");
打印出测试文件,但这个方法有时能成功,有时又不行.如果不行的话就只能用第一种方法慢慢调了
Project1
Task #1 Extendible Hash Table
这一部分内容是实现可拓展哈希,至于为什么不直接使用stl中的unordered_map,我的猜测是unordered_map在动态增长时是不可控的,而我们自己实现的可拓展哈希在容量不够时从1个bucket分裂成2个bucket,每次容量增加大小即为一个bucket的大小. 因此我们能够实现更精细化的管理
第一遍没跑通的原因是在==Insert==函数下如果bucket容量满了需要分裂,忘记写上num_bucket++
Task #2 - LRU-K Replacement Policy
这节任务主要是在数据库内部实现自己的内存页管理策略,而不是交由操作系统来管理. 上过课的都知道,数据库相比操作系统更接近用户端,更能明白哪些数据库页是接下来还会用到的,哪些页是可以淘汰的,因此在数据库内管理页能比操作系统效率更高
第一次做的时候,在函数==SetEvictable==中没有判断传入的frame_id是否在lru-k的管理系统中,导致如果传入了一个没有使用的frame_id,函数并没有退出,而是新建了一个管理表项,导致后面出现了bug
Project 2
https://zhuanlan.zhihu.com/p/592964493这个链接里博主用图直观展示了B+树相关操作,便于理解
Checkpoint 1
- InternalPage 的size由什么决定
第一个key为空也算1个元素
- 新增一个internalPage或者leafPage时,应该修改哪些变量
Size parentNode page_type
- Merge将两个节点合并成一个,如何将节点删除
UnpinPage后是否要DeletePage?这个问题并没找到答案,最后我没有使用DeletePage,这代表被删除的页的页号是被占用的,无法分配给新页
Checkpoint 2
- 加锁是在Page*这一层加,Page的data部分是BPlusTreePage,需要弄清楚这个层次关系
- 参考https://zhuanlan.zhihu.com/p/580014163的回答
以下是我在debug中修改的地方,覆盖了一些常见错误
-
Insert和Remove涉及到创建或者删除节点时,要记得更新子节点的父节点(更新子节点是否加锁)
-
一定要记得unpin
-
非根节点成为根节点后,要更新父节点为INVALID_PAGE_ID
-
parent_page->SetSize(mid_index - 1); parent_page->Insert(key, new_node->GetPageId(), comparator_);在向Internal_Page插入之前忘记更新节点的size,导致插入的key-value位置不对
-
Index_iterator要考虑空树的情况,空树的Begin()和End()要用特殊的index_iterator记录
-
在FindLeafPage函数中有一段原本写法如下所示,先判断子节点的大小是否满足安全节点特征再上锁,这可能存在race condition。在判断和上锁这个时间间隔中可能子节点的内容会改变,因此要把对子节点的上锁提到判断之前
if (operation == Operation::INSERT_PESSI) { // insert时对leafpage加写锁
if (child_node->IsLeafPage() && child_node->GetSize() < child_node->GetMaxSize() - 2) {
child_page->WLatch();
ReleaseLatchFromQueue(transaction);
return child_page;
}
if (child_node->IsLeafPage()) {
child_page->WLatch();
return child_page;
}
if (child_node->GetSize() < child_node->GetMaxSize() - 1) { // 中间节点为安全节点
child_page->WLatch();
ReleaseLatchFromQueue(transaction);
transaction->AddIntoPageSet(child_page);
} else {
child_page->WLatch();
transaction->AddIntoPageSet(child_page);
}
// child_page->WLatch();
// transaction->AddIntoPageSet(child_page);
}
-
IndexIterator在使用copy assignment operator例如
auto itr = Index->Begin()应该将iterator对应页的读锁也复制一遍,否则等号右边为rvalue,在析构后会释放读锁,导致itr对应的页此时没有上读锁
Checkpoint2 在经历两周debug后仍然没有找到问题所在,分数一直是45分。无奈之下,为了不做无谓的消耗,只得将自己的代码存档,拼补了别人写的Insert和Remove函数,希望之后哪天闲着没事再来修理这屎坑
Project 4
task1
出现的问题
-
LockRequestQueue中的request_queue_并不是智能指针队列,所以向其中插入的时候要用new,删除的时候要记得delete,否则会造成内存泄漏(update:为了便于管理,后续将LockRequestQueue改为智能指针队列)
-
UnlockRow的时候要注意,transaction中记录row的持锁情况的数据结构为
/** LockManager: the set of row locks held by this transaction. */ std::shared_ptr<std::unordered_map<table_oid_t,std::unordered_set<RID>>> s_row_lock_set_; std::shared_ptr<std::unordered_map<table_oid_t,std::unordered_set<RID>>> x_row_lock_set_;原本我在删除一个row锁时会判断oid对应的row锁是否为空,空的话就在s_row_lock_set_或者x_row_lock_set_中将oid表项进行删除
txn->GetSharedRowLockSet()->operator[](oid).erase(rid); if (txn->GetSharedRowLockSet()->operator[](oid).empty()) { txn->GetSharedRowLockSet()->erase(oid); }在UnlockTable的时候要判断该表下是否有row持锁,只需判断s_row_lock_set_或者x_row_lock_set_是否为空即可。然而测试样例中检查row持锁情况CheckTxnRowLockSize函数为
EXPECT_EQ((*(txn->GetSharedRowLockSet()))[oid].size(), shared_size); EXPECT_EQ((*(txn->GetExclusiveRowLockSet()))[oid].size(), exclusive_size);unordered_map m中如果key不存在,m[key]会导致新增一个表项,使得UnlockTable判断失效。解决方法只需将UnlockRow的时候即使oid中所有row都不持锁,也不清理对应oid表项。UnlockTable中的判断条件改为
txn->GetSharedRowLockSet()->operator[](oid).size()==0 -
原本只在UnlockTable和UnlockRow的时候使用notify_all唤醒等待的线程,但实际上在LockTable和LockRow中,如果当前线程在升级锁,完成升级后也要唤醒等待线程。这是因为升级锁线程默认优先级最高,升级完成后要及时把优先级转让给其他线程
-
在获取到oid对应的table_lock_map后不要着急把 table_lock_map_latch释放掉,应该先拿到LockRequestQueue的锁后再释放
疑问
- LockTable、LockRow这些操作是由谁发出的?Transaction吗?
由executor发起
task2
本任务是设计一个死锁检测,lock_manager后台有一个死锁检测线程,隔断时间后会苏醒检查当前是否存在死锁,若存在则让transaction_id最大的transaction abort。死锁检测的原理是将当前所有transaction持有锁和等待锁的关系用一个有向图表示,比如t1在等待t2持有的X锁释放,那么用一条t1指向t2的边表示。再用DFS算法检测当前有向图是否存在环从而判断死锁。 lock_manager并不需要实时维护一个有向图,只需在死锁检测线程苏醒后实时构建即可。
学习笔记
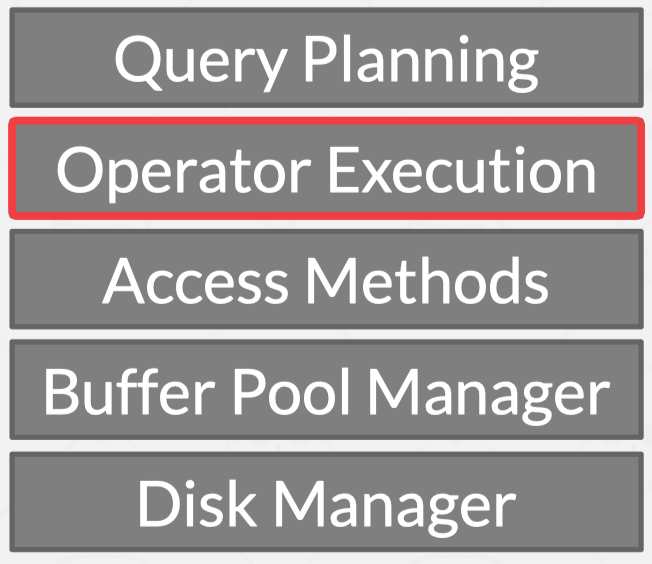
- DBMS的主要5个层次
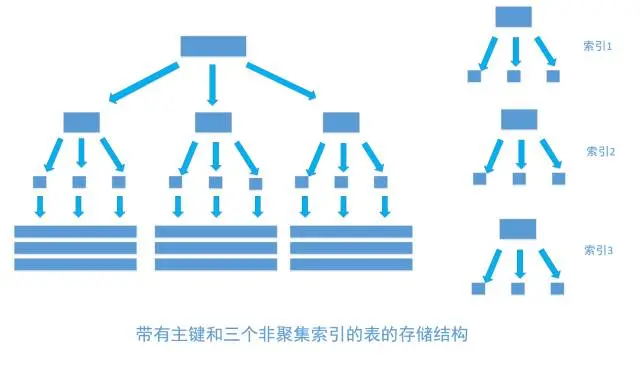
- 非聚集索引和聚集索引的区别
通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据
- #10中提到,DBMS在处理聚合函数时有两种策略,一种是排序,然后将重复的key进行分组.这种方式的弊端是distinct,group by等函数是不需要输出结果有序的,排序无疑增加了计算量.第二种策略是哈希.如果所有元素都能装进内存并生成hash table那自然最好,那如果元素很多不能全部放进内存呢?
课上介绍了一种先进行partition,再进行rehash的方法.


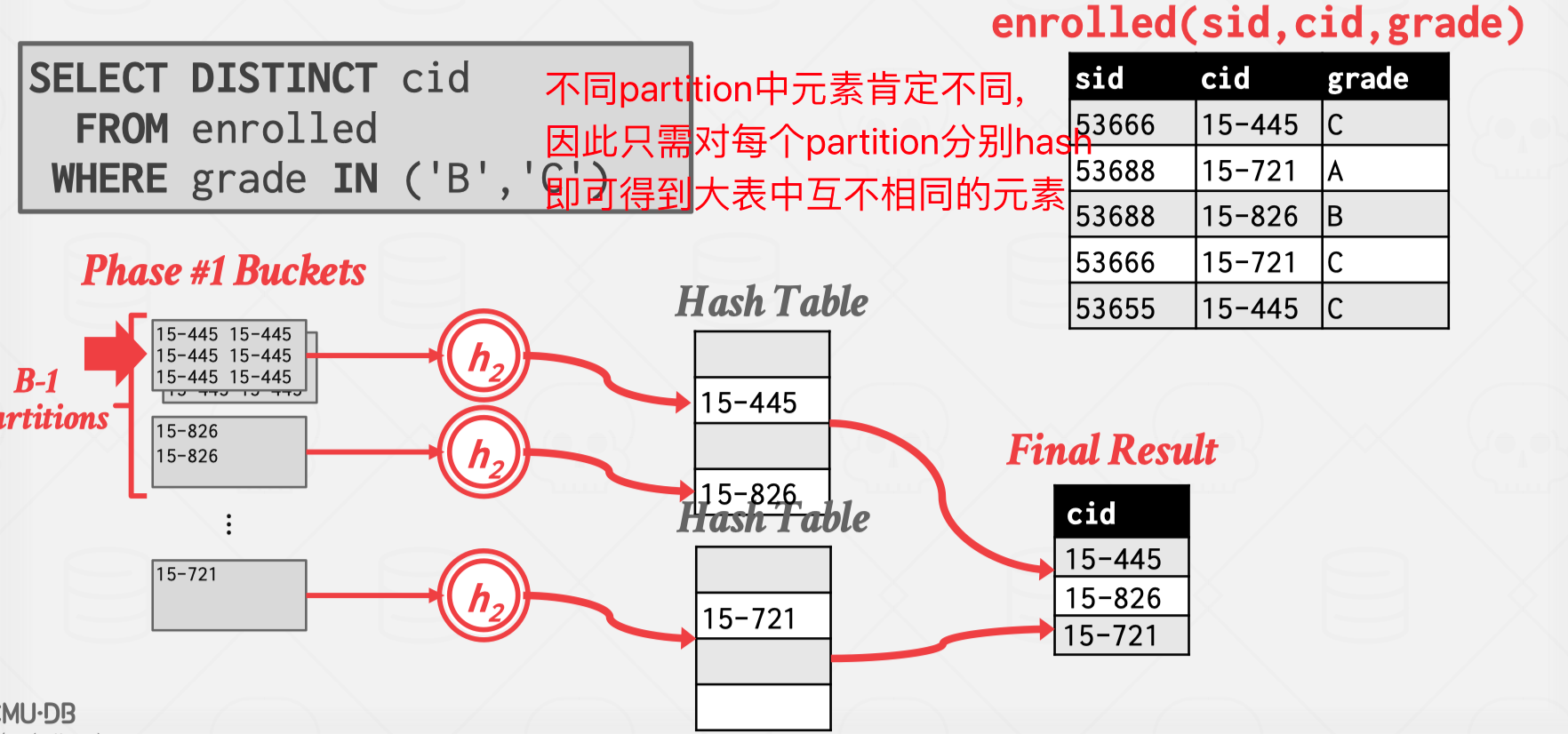
主要思想和外部排序一样,将大的表先分成小块,再对每个小块进行哈希,最后将结果汇总
- Query的并发执行
process per worker:操作系统管理进程的调度
thread per worker:DBMS管理query分配给什么线程
Query Planning & Optimization
- Rules
根据一些规则对query进行优化
- Cost-based Search
根据已有数据去估计执行时间
Concurrency control
- Lock
- Timestamp
Recovery
Distributed
- share everything
- share memory
- share disk
- share nothing
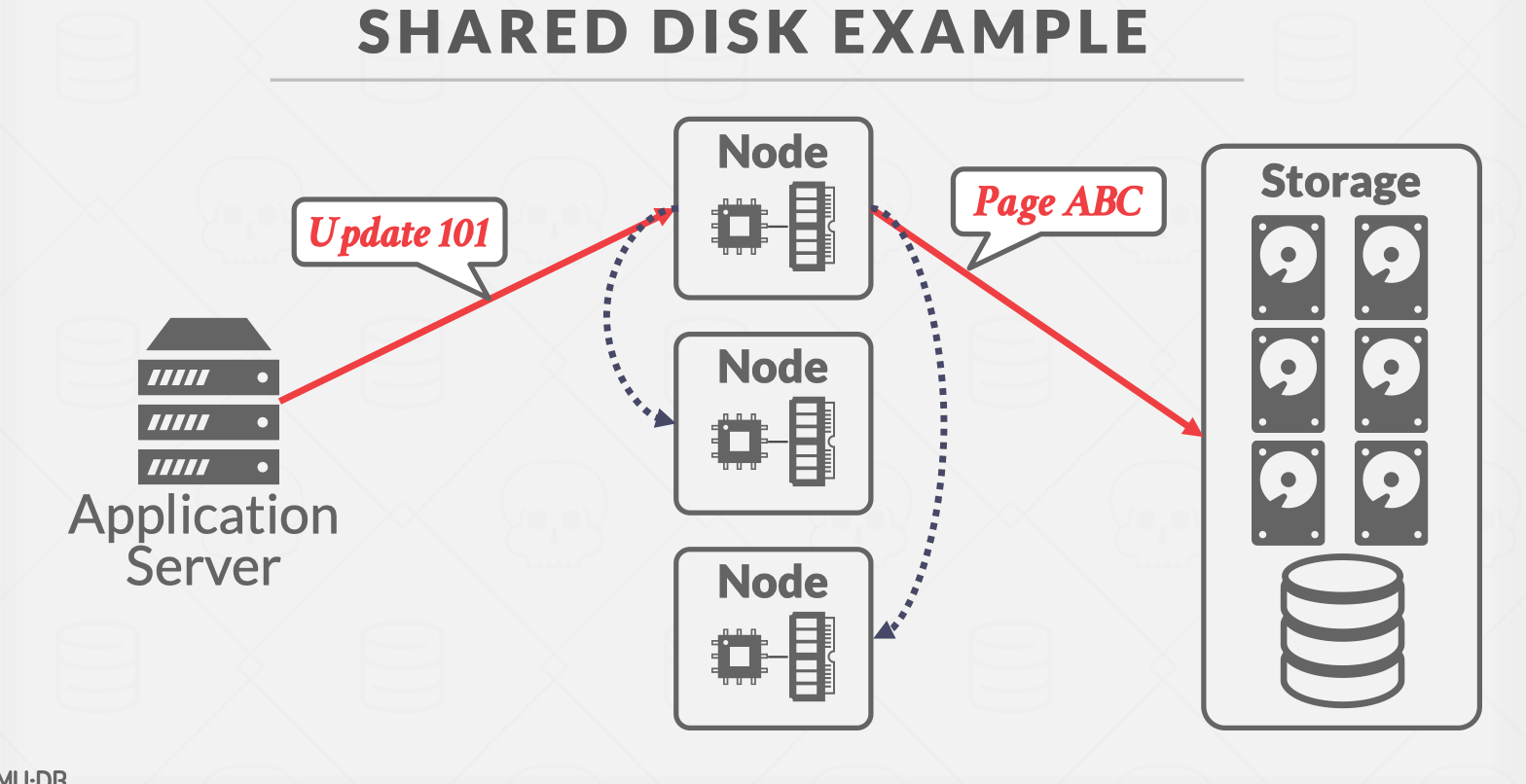
将计算层和存储层进行解耦,方便拓展
