
MIT6824 spring 2023 lab4记录
lab4
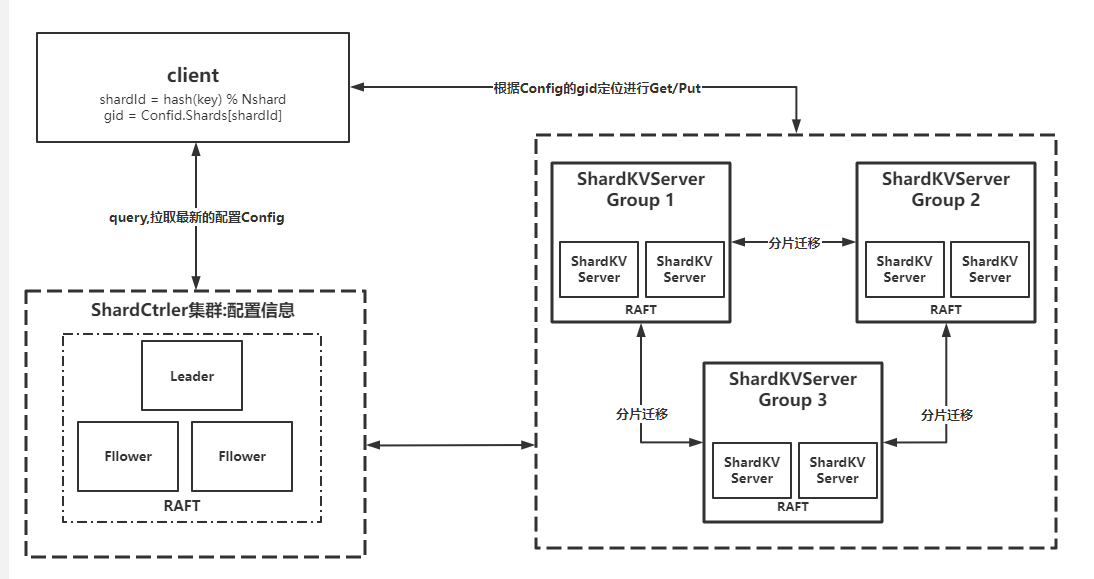 lab4 做的时候因为快开学了,比较赶时间,借鉴了这篇[博客](https://www.cnblogs.com/pxlsdz/p/15685837.html)中的一些思路,上面博客作者画的 lab4 的架构图
lab4 做的时候因为快开学了,比较赶时间,借鉴了这篇[博客](https://www.cnblogs.com/pxlsdz/p/15685837.html)中的一些思路,上面博客作者画的 lab4 的架构图
lab4A 实现的是左半边的内容,处理 client 和 shardCtrler 之间的通信,包括 Query、Join、Leave、Move 这 4 个 RPC。shardCtrler 管理着数据分片的一些信息,比如某个 shard 具体保存在哪个 group 上,client 知道这个信息后就可以直接向对应的 group 索要数据
lab4A
lab4A 整体实现与 lab3 基本相同,但是不用考虑 snapshot 实现会更简单,最主要的难点是如何在group 有变化后进行负载均衡,要求有三点
- 每个 group 对应的 shard 要尽可能平均,隐含信息为对应 shard 最多的 group 和最少的 group 之间最多差 1 个 shard
- 负载均衡时,移动的分片要尽可能少
- 不同服务器进行负载均衡的算法要保证确定性,相同的状态在进行负载均衡后的状态也应该一样
实现方法是构造一个 g2s map,映射关系为 gid ->保存的 shard,然后以确定性的方法遍历这个 map,循环将保存 shard 最多的 group 转移一个 shard 到保存 shard 最少的 group 上,直到最多的 group 和最少的 group 之间的差值小于等于 1 才结束循环
func (sc *ShardCtrler) applyJoin(groups map[int][]string) {
lastConfig := sc.configs[len(sc.configs)-1]
newConfig := Config{len(sc.configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
for gid, servers := range groups {
if _, ok := newConfig.Groups[gid]; !ok {
newServers := make([]string, len(servers))
copy(newServers, servers)
newConfig.Groups[gid] = newServers
}
}
// gid-> shard
g2s := groupToShards(newConfig)
// rebalance
// make gid with most shards
for {
s, t := getMaxNumShardByGid(g2s), getMinNumShardByGid(g2s)
if s != 0 && len(g2s[s])-len(g2s[t]) <= 1 {
break
}
g2s[t] = append(g2s[t], g2s[s][0])
g2s[s] = g2s[s][1:]
}
var newShards [NShards]int
for gid, shards := range g2s {
for _, shardId := range shards {
newShards[shardId] = gid
}
}
newConfig.Shards = newShards
sc.configs = append(sc.configs, newConfig)
}
func groupToShards(config Config) map[int][]int {
g2s := make(map[int][]int)
for gid := range config.Groups {
g2s[gid] = make([]int, 0)
}
for shardId, gid := range config.Shards {
g2s[gid] = append(g2s[gid], shardId)
}
return g2s
}
func deepCopy(groups map[int][]string) map[int][]string {
newGroups := make(map[int][]string)
for gid, servers := range groups {
newServers := make([]string, len(servers))
copy(newServers, servers)
newGroups[gid] = newServers
}
return newGroups
}
func getMinNumShardByGid(g2s map[int][]int) int {
// 不固定顺序的话,可能会导致两次的config不同
gids := make([]int, 0)
for key := range g2s {
gids = append(gids, key)
}
sort.Ints(gids)
min, index := NShards+1, -1
for _, gid := range gids {
if gid != 0 && len(g2s[gid]) < min {
min = len(g2s[gid])
index = gid
}
}
return index
}
func getMaxNumShardByGid(g2s map[int][]int) int {
// GID = 0 是无效配置,一开始所有分片分配给GID=0
if shards, ok := g2s[0]; ok && len(shards) > 0 {
return 0
}
gids := make([]int, 0)
for key := range g2s {
gids = append(gids, key)
}
sort.Ints(gids)
max, index := -1, -1
for _, gid := range gids {
if len(g2s[gid]) > max {
max = len(g2s[gid])
index = gid
}
}
return index
}
还有一个小细节要注意的是,Config 中的 Groups 项是一个 map[int][]string的 map,因为 map 的 value 是个数组,如果用拷贝赋值的方式创建新的 Config,那么 value 实际上还是旧的 value,所以这里要用深拷贝
lab4B
主要代码结构
applyFuncs.go主要是一些处理底层 raft apply 上来数据的函数
// 处理配置更新
func (kv *ShardKV) applyConfiguration(nextConfig *shardctrler.Config) *CommandResponse {
if nextConfig.Num == kv.currentConfig.Num+1 {
kv.updateShardStatus(nextConfig)
kv.lastConfig = kv.currentConfig
kv.currentConfig = *nextConfig
Debug(dInfo, "G%d S%d .updates currentConfig from %d to %d", kv.gid, kv.me, kv.lastConfig.Num, kv.currentConfig.Num)
return &CommandResponse{OK, ""}
}
return &CommandResponse{ErrOutDated, ""}
}
// 处理客户端的操作
func (kv *ShardKV) applyOperation(op *Op) *CommandResponse {
response := &CommandResponse{Err: OK}
shardID := key2shard(op.Key)
status := kv.canServe(shardID)
if status == OK {
switch op.Operation {
case "Get":
response.Value, response.Err = kv.stateMachines[shardID].Get(op.Key)
if op.MsgID > kv.LastMsgID[op.ClientID] {
kv.LastMsgID[op.ClientID] = op.MsgID
}
return response
case "Put":
if op.MsgID > kv.LastMsgID[op.ClientID] {
response.Err = kv.stateMachines[shardID].Put(op.Key, op.Value)
kv.LastMsgID[op.ClientID] = op.MsgID
}
return response
case "Append":
if op.MsgID > kv.LastMsgID[op.ClientID] {
response.Err = kv.stateMachines[shardID].Append(op.Key, op.Value)
kv.LastMsgID[op.ClientID] = op.MsgID
}
return response
}
}
return &CommandResponse{status, ""}
}
// 处理分片迁移 pull 过来的数据
func (kv *ShardKV) applyInsertShards(shardsInfo *ShardOperationResponse) *CommandResponse {
if shardsInfo.ConfigNum == kv.currentConfig.Num {
for shardId, shardData := range shardsInfo.Shards {
if kv.stateMachines[shardId].Status == Pulling {
kv.stateMachines[shardId].KV = deepCopy(shardData)
kv.stateMachines[shardId].Status = Serving
}
}
for clientID, msgID := range shardsInfo.LastMsgID {
if lastmsgID, ok := kv.LastMsgID[clientID]; !ok || msgID > lastmsgID {
kv.LastMsgID[clientID] = msgID
}
}
return &CommandResponse{OK, ""}
}
return &CommandResponse{ErrOutDated, ""}
}
// 分片迁移后清理状态机
func (kv *ShardKV) applyDeleteShards(shardsInfo *ShardOperationRequest) *CommandResponse {
if shardsInfo.ConfigNum == kv.currentConfig.Num {
for _, shardId := range shardsInfo.ShardIDs {
shard := kv.stateMachines[shardId]
if shard.Status == BePulled {
kv.stateMachines[shardId] = NewShard()
}
}
return &CommandResponse{OK, ""}
}
return &CommandResponse{OK, ""}
}
goroutings.go中的函数为在后台循环运行的 go routine
// 包装起来的一个函数,作用是以 interval 为间隔,循环执行 funcPtr 函数,且要求自身为 leader
func (kv *ShardKV) Monitor(funcPtr func(), interval time.Duration) {
for {
// only leader need to run go routine
if _, isLeader := kv.rf.GetState(); isLeader {
if kv.Killed() {
return
}
funcPtr()
}
time.Sleep(interval)
}
}
// 向 shardctrler 拉取最新的配置
func (kv *ShardKV) queryConfig() {
canPerformNextConfig := true
kv.mu.RLock()
for _, shard := range kv.stateMachines {
if shard.Status != Serving {
canPerformNextConfig = false
// DPrintf("{Node %v}{Group %v} will not try to fetch latest configuration because shards status are %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), kv.currentConfig)
break
}
}
currentConfigNum := kv.currentConfig.Num
kv.mu.RUnlock()
if canPerformNextConfig {
nextConfig := kv.sc.Query(currentConfigNum + 1)
// nextConfig := kv.sc.Query(-1)
if nextConfig.Num == currentConfigNum+1 {
// Debug(dInfo, "G%d S%d updates currentConfig from %d to %d,config is %v", kv.gid, kv.me, kv.currentConfig.Num, nextConfig.Num, nextConfig)
kv.Execute(NewConfigurationCommand(&nextConfig), &CommandResponse{})
}
}
}
// 检查状态机中状态为 pulling 的分片,去对应的 server 上拉取分片
func (kv *ShardKV) migrationShard() {
kv.mu.RLock()
gid2shardIDs := kv.getShardIDsByStatus(Pulling)
var wg sync.WaitGroup
for gid, shardIDs := range gid2shardIDs {
Debug(dServer, "G%d S%d pull shards %v from gid:G%d", kv.gid, kv.me, shardIDs, gid)
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
pullTaskRequest := ShardOperationRequest{configNum, shardIDs}
for _, server := range servers {
var pullTaskResponse ShardOperationResponse
srv := kv.make_end(server)
if srv.Call("ShardKV.GetShardsData", &pullTaskRequest, &pullTaskResponse) && pullTaskResponse.Err == OK {
var response CommandResponse
kv.Execute(NewInsertShardsCommand(&pullTaskResponse), &response)
if response.Err == OK {
// 成功之后是否应该通知对方删除数据
go kv.notifyGC(servers, &pullTaskRequest)
return
}
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait()
}
// 分片迁移结束后,通知原 group 清理分片
func (kv *ShardKV) notifyGC(servers []string, req *ShardOperationRequest) {
index := 0
for {
server := servers[index]
srv := kv.make_end(server)
for i := 0; i < kv.retry; i++ {
var gcResponse CommandResponse
ok := srv.Call("ShardKV.GCshards", req, &gcResponse)
if ok {
if gcResponse.Err == OK {
return
}
if gcResponse.Err == ErrWrongLeader {
break
}
}
}
index = (index + 1) % len(servers)
}
}
// 循环执行 raft 层 apply 的数据
func (kv *ShardKV) applyLoop() {
for apply := range kv.applyCh {
if kv.Killed() {
return
}
if apply.SnapshotValid {
// Debug(dSnap, "S%d restore snapshot", kv.me)
kv.readSnapshot(apply.Snapshot)
continue
}
if !apply.CommandValid {
continue
}
command := apply.Command.(Command)
kv.mu.Lock()
var response *CommandResponse
switch command.Op {
case Operation:
operation := command.Data.(Op)
response = kv.applyOperation(&operation)
case Configuration:
config := command.Data.(shardctrler.Config)
response = kv.applyConfiguration(&config)
case InsertShards:
insertShardsResponse := command.Data.(ShardOperationResponse)
response = kv.applyInsertShards(&insertShardsResponse)
case DeleteShards:
deleteShardsRequest := command.Data.(ShardOperationRequest)
response = kv.applyDeleteShards(&deleteShardsRequest)
}
term, isLeader := kv.rf.GetState()
// notify rpc handler
if _, ok := kv.NotifyChan[apply.CommandIndex]; ok && isLeader && term == apply.CommandTerm {
kv.NotifyChan[apply.CommandIndex] <- *response
}
kv.mu.Unlock()
// snapshot
if kv.maxraftstate != -1 && kv.persister.RaftStateSize() > kv.maxraftstate {
kv.saveSnap(apply.CommandIndex)
}
}
}
rpchandler.go
func (kv *ShardKV) Get(args *GetArgs, reply *GetReply) {
// Your code here.
kv.mu.RLock()
shardID := key2shard(args.Key)
shardStatus := kv.canServe(shardID)
if shardStatus != OK {
reply.Err = shardStatus
reply.Value = ""
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
op := Op{Operation: "Get", ClientID: args.ClientID, MsgID: args.MsgID, Key: args.Key}
response := CommandResponse{}
kv.Execute(NewOperationCommand(&op), &response)
reply.Err = response.Err
reply.Value = response.Value
}
func (kv *ShardKV) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
kv.mu.RLock()
shardID := key2shard(args.Key)
shardStatus := kv.canServe(shardID)
if shardStatus != OK {
reply.Err = shardStatus
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
op := Op{Operation: args.Op, ClientID: args.ClientID, MsgID: args.MsgID, Key: args.Key, Value: args.Value}
command := Command{Op: Operation, Data: op}
response := CommandResponse{}
kv.Execute(command, &response)
reply.Err = response.Err
}
func (kv *ShardKV) GetShardsData(request *ShardOperationRequest, response *ShardOperationResponse) {
// only pull shards from leader
if _, isLeader := kv.rf.GetState(); !isLeader {
response.Err = ErrWrongLeader
return
}
kv.mu.RLock()
defer kv.mu.RUnlock()
if kv.currentConfig.Num != request.ConfigNum {
response.Err = ErrNotReady
return
}
response.Shards = make(map[int]map[string]string)
for _, shardID := range request.ShardIDs {
if kv.stateMachines[shardID].Status != BePulled {
response.Err = ErrOutDated
return
}
response.Shards[shardID] = deepCopy(kv.stateMachines[shardID].KV)
}
response.LastMsgID = make(map[int64]int)
for k, v := range kv.LastMsgID {
response.LastMsgID[k] = v
}
response.ConfigNum, response.Err = request.ConfigNum, OK
}
func (kv *ShardKV) GCshards(request *ShardOperationRequest, response *CommandResponse) {
if _, isLeader := kv.rf.GetState(); !isLeader {
response.Err = ErrWrongLeader
return
}
kv.mu.RLock()
if kv.currentConfig.Num != request.ConfigNum {
if kv.currentConfig.Num < request.ConfigNum {
response.Err = ErrNotReady
} else { // if currentConfig.Num > request.ConfigNum means old shard has been deleted
response.Err = OK
}
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
kv.Execute(NewDeleteShardsCommand(request), response)
}
shard.go 将分片抽象成一个 Shard 结构
type Shard struct {
KV map[string]string
Status ShardStatus
}
func NewShard() *Shard {
return &Shard{make(map[string]string), Serving}
}
func (shard *Shard) Get(key string) (string, Err) {
if value, ok := shard.KV[key]; ok {
return value, OK
}
return "", ErrNoKey
}
func (shard *Shard) Put(key, value string) Err {
shard.KV[key] = value
return OK
}
func (shard *Shard) Append(key, value string) Err {
shard.KV[key] += value
return OK
}
common.go存储着一些常量和参数定义
const (
OK = "OK"
ErrNoKey = "ErrNoKey"
ErrWrongGroup = "ErrWrongGroup"
ErrWrongLeader = "ErrWrongLeader"
CurUnvalable = "CurUnvalable"
TimeOut = "TimeOut"
ErrOutDated = "ErrOutDated"
ErrNotReady = "ErrNotReady"
)
// go routine interval
const (
ConfigureQueryInterval = 90 * time.Millisecond
MigrationShardInterval = 50 * time.Millisecond
WaitingInterval = 70 * time.Millisecond // wait for config to catch up
)
type Err string
type ShardStatus uint8
const (
Serving ShardStatus = iota
Pulling
BePulled
// NeedGC // shard need to be garbage collected
)
type CommandResponse struct {
Err Err
Value string
}
// Put or Append
type PutAppendArgs struct {
Key string
Value string
Op string // "Put" or "Append"
ClientID int64
MsgID int
}
type PutAppendReply struct {
Err Err
}
type GetArgs struct {
Key string
ClientID int64
MsgID int
}
type GetReply struct {
Err Err
Value string
}
type ShardOperationRequest struct {
ConfigNum int
ShardIDs []int
}
type ShardOperationResponse struct {
Shards map[int]map[string]string
ConfigNum int
Err Err
LastMsgID map[int64]int
}
遇到的问题
- config应该逐个更新吗?还是可以跨越式的更新
应该逐个按次更新,否则无法及时拉取之前的数据
- lastMsgID需要在分片迁移时跟着迁移吗?
需要。比如 gid A 中的 MsgID 已经执行到 10,gid B 中的 MsgID 为 8。当发生分片迁移时,gid A 中的分片被传输到 gid B 中,这时 gid B 中的状态已经更新为 MsgID=10 时候的状态,可是 lastMsgID 没有对应更新,这时如果收到网络中延时到达的 MsgID=9 的数据包,那么 gid B 就会重复执行
