
MIT6824 spring 2023 lab3记录
lab3
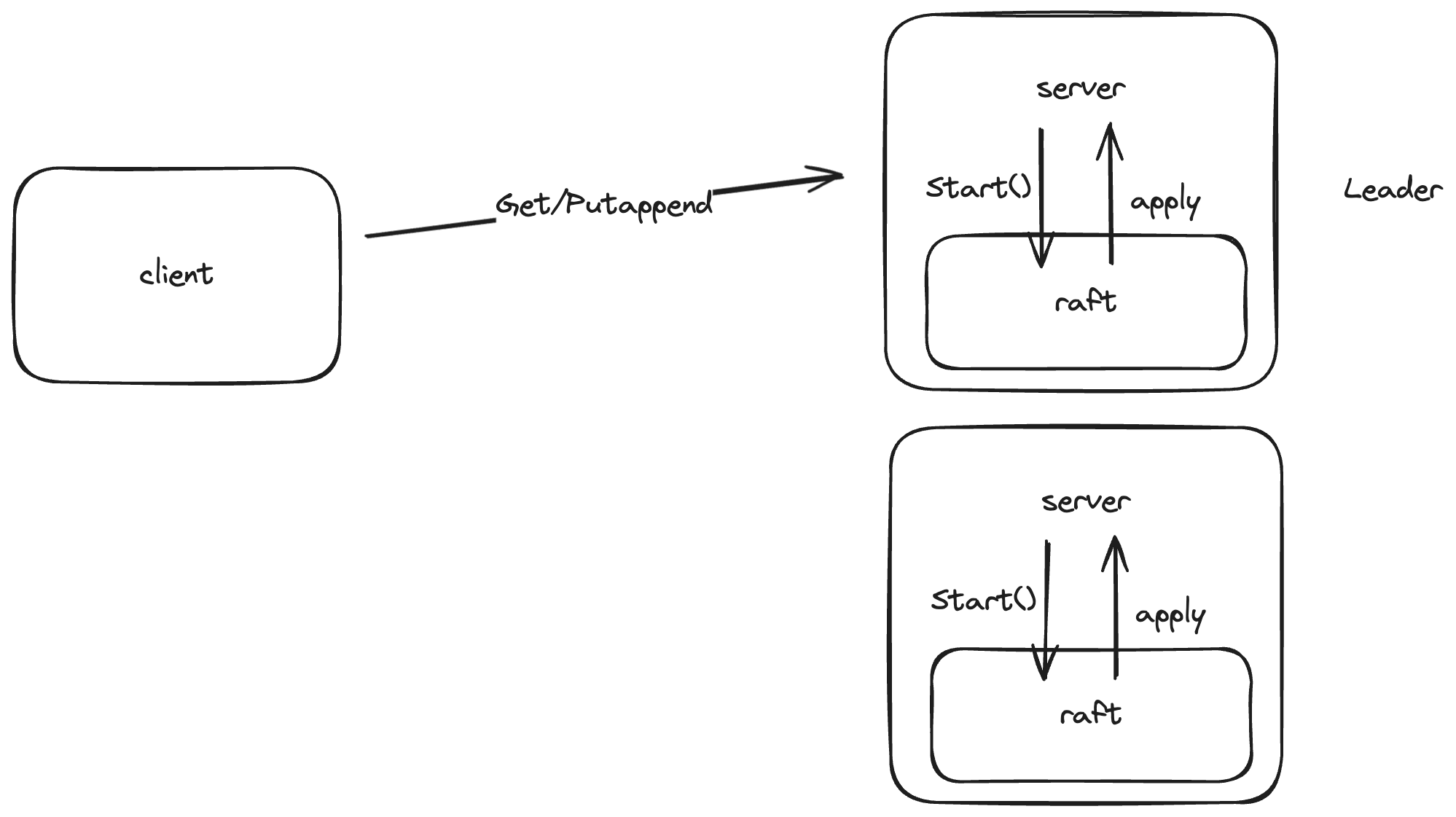
lab3 在 lab2 的基础上实现一个上层的 kv 存储服务,有 client 和 server 两个新角色。client 有 get 和 putappend 两种操作,当 client 首先向随机的一个 server 发起请求,如果这个 server 不是 raft 中的 leader 则返回失败,client 再向另一个 server 发起请求,直到请求到达 leader。server 接收到请求后,会调用下层 raft 协议中的 Start() 函数,直到这个请求被 raft 网络中的大多数节点 commit 并随后 apply 给上层 server 后,server 才会向 client 返回结果
Lab3的实现参考了这篇博客https://github.com/OneSizeFitsQuorum/MIT6.824-2021/blob/master/docs/lab3.md,上面有一些注意事项值得参考
lab3A
3A 要解决的问题主要有:
- 要考虑 rpc 包丢失,服务器宕机等情况
- 从 server 接收到 client 的请求,到状态机执行这个操作中间有一段时间,在操作执行之后应该如何通知等待的请求
- 重复指令的检测
- 如何将 raft apply 的指令应用于状态机
我想到的设计为,server 需要有一个 applyLoop 的 goroutine,在后台循环检测下层 raft apply 的指令,如果判断该指令不是重复的指令,就把它运用于状态机上,随后将执行结果返回给等待的 client 请求
func (kv *KVServer) applyLoop() {
for apply := range kv.applyCh {
if kv.killed() {
return
}
if !apply.CommandValid {
continue
}
op := apply.Command.(Op)
clientID := op.ClientID
msgID := op.MsgID
executeResult := executeResult{}
kv.mu.Lock()
if op.Operation == "Put" && msgID > kv.LastMsgID[clientID] {
kv.KVStore[op.Key] = op.Value
kv.LastMsgID[clientID] = msgID
} else if op.Operation == "Append" && msgID > kv.LastMsgID[clientID] {
kv.KVStore[op.Key] += op.Value
kv.LastMsgID[clientID] = msgID
} else if op.Operation == "Get" {
if _, ok := kv.KVStore[op.Key]; !ok {
executeResult.err = ErrNoKey
} else {
executeResult.value = kv.KVStore[op.Key]
}
if msgID > kv.LastMsgID[clientID] {
kv.LastMsgID[clientID] = msgID
}
}
term, isLeader := kv.rf.GetState()
// notify rpc handler
if _, ok := kv.NotifyChan[apply.CommandIndex]; ok && isLeader && term == apply.CommandTerm {
kv.NotifyChan[apply.CommandIndex] <- executeResult
}
kv.mu.Unlock()
}
}
对于重复指令的检测,用了一个LastMsgID map[int64]int的 map 来记录每个 client 已经执行的指令的最大序号。但这里有个问题我没有去解决,一个是什么时候可以清除某个 client 的记录,比如 client 在向 server 发送两个 rpc 请求后就再也不发送指令了,那么需要能够清除这个 client 表项以防止内存的浪费。一种可能的解决方法是,用一个 session 保存每个 client 生命周期内的状态,当 session 结束,就把对应的表项清除。session 的退出由具体的应用来确定,可以是 client 主动发送一个退出的指令,也可以用心跳机制比如 10 分钟没有交互就退出 session。
func (kv *KVServer) Get(args *GetArgs, reply *GetReply) {
command := Op{Operation: "Get", ClientID: args.ClientID, MsgID: args.MsgID, Key: args.Key}
index, _, isLeader := kv.rf.Start(command)
if !isLeader {
reply.Err = ErrWrongLeader
reply.Value = ""
return
}
kv.mu.Lock()
if kv.NotifyChan[index] == nil {
kv.NotifyChan[index] = make(chan executeResult, 1)
}
notifyChan := kv.NotifyChan[index]
kv.mu.Unlock()
select {
case res := <-notifyChan:
if res.err == ErrNoKey {
Debug(dWarn, "No key")
reply.Err = ErrNoKey
} else {
reply.Err = OK
reply.Value = res.value
}
case <-time.After(500 * time.Millisecond):
reply.Err = TimeOut
}
kv.mu.Lock()
close(kv.NotifyChan[index])
delete(kv.NotifyChan, index)
kv.mu.Unlock()
}
get 和 putappend rpc handler 的基本流程如上,在调用 raft 的 Start() 函数后判断自身是否为 leader,如果不是则立即返回。接着就可以在对应 index 上创建一个 channel,等待 applyLoop 通知指令执行完成。之所以这样能确保 applyLoop 和 rpc handler的一一对应关系,是因为 index 和每条指令是一一对应的,这是由下层 raft 协议确保的每个服务器中每个相同 index 中存储的指令都相同。这里还有一点要注意,rpc handler 不能无限等待,因为可能下层 raft 已经不是 leader 了,就不会通知上层。所以要设置一个超时时间,超过之后也返回。
遇到的一些问题
- 检测重复指令应该在什么时候进行?
一开始想到了两种方式
- 在 raft 将重复的 log apply给上层后,由 server 根据 cilentID 和 MsgID 判断是否是重复指令,如果重复就不执行
- server 调用 raft 的 Start() 函数之前,如果发现这条 log 已经执行过,则不进行 log replication
方法 2 可以避免重复的指令进行 log replication但不保证一定能发现重复的指令,因为只有在状态机执行指令后,server 才会更新每个 client 最新执行的 MsgID。之前重复的指令可能已经 commit,但还没有 apply 给上层状态机,所以 server 并没有发现这是一条重复指令,仍然会进行 log replication
我的方法是两种方式结合来用,如果方法 2 发现当前指令是重复指令,那么直接返回结果,不需要再调用 Start()函数。就算方法 2 没有发现,方法 1 能保证不执行过相同的指令
- 客户端从 server 处收到了 Put 指令成功执行的结果,但随后查询却并没有 put 进去的这个值
server 通过 channel 通知客户端的 RPC 请求时,要判断目前是否是 Leader,且当前 term 与log 中的 term 一致才能通知客户端,否则可能出现本地 log 对应的客户端,与等待客户端不一致的情况。比如客户端 C1 给 S1 发送了 Put(‘1’,‘x’) 的指令,S1 返回的 index 为 3,这时服务端 S1 就会创建一个 index 为 3 的 channel,当 index 为 3 的指令 apply 后通知等待的 C1.然而有一种情况是,因为 partition 等情况,实际上 S2 才是当前网络中的 Leader,S2 中 index 为 3 的指令为 Put(‘1’,‘y’) ,那么这条指令会覆盖 S1 中 C1 的指令并 apply,如果 S1 通知 C1 Put 操作成功,那么状态机中实际的值为 key=1,value=y,就会出现不一致的情况
lab3B
lab3B 在 3A 的基础上引入了 snapshot,需要修改一下 applyLoop 函数,判断 raft 当前 apply 的是指令还是 snapshot,在函数最后,需要判断当前 raft 状态字节数是否超过给定值,是的话就要把当前状态保存成 snapshot,传递给 raft 进行同步
func (kv *KVServer) applyLoop() {
for apply := range kv.applyCh {
if kv.killed() {
return
}
if apply.SnapshotValid {
kv.readSnapshot(apply.Snapshot)
continue
}
if !apply.CommandValid {
continue
}
// 省略中间执行指令的过程
// snapshot
if kv.maxraftstate != -1 && kv.persister.RaftStateSize() > kv.maxraftstate {
kv.saveSnap(apply.CommandIndex)
}
}
}
考虑到服务器可能宕机,在 StartKVServer() 函数中要调用 readSnapshot() 读取 persister 中保存的 snapshot
func (kv *KVServer) readSnapshot(data []byte) {
Debug(dSnap, "S%d read snapshot", kv.me)
if data == nil || len(data) < 1 {
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var kvStore map[string]string
var lastMsgID map[int64]int
if d.Decode(&kvStore) != nil || d.Decode(&lastMsgID) != nil {
} else {
kv.KVStore = kvStore
kv.LastMsgID = lastMsgID
}
}
func (kv *KVServer) saveSnap(index int) {
kv.mu.RLock()
defer kv.mu.RUnlock()
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(kv.KVStore)
e.Encode(kv.LastMsgID)
data := w.Bytes()
kv.rf.Snapshot(index, data)
}
