
MIT6824 spring 2023 lab1 lab2记录
debug用了https://blog.josejg.com/debugging-pretty/这个方法,在多线程编程中能更直观地看出各个节点之间的交互和时序关系
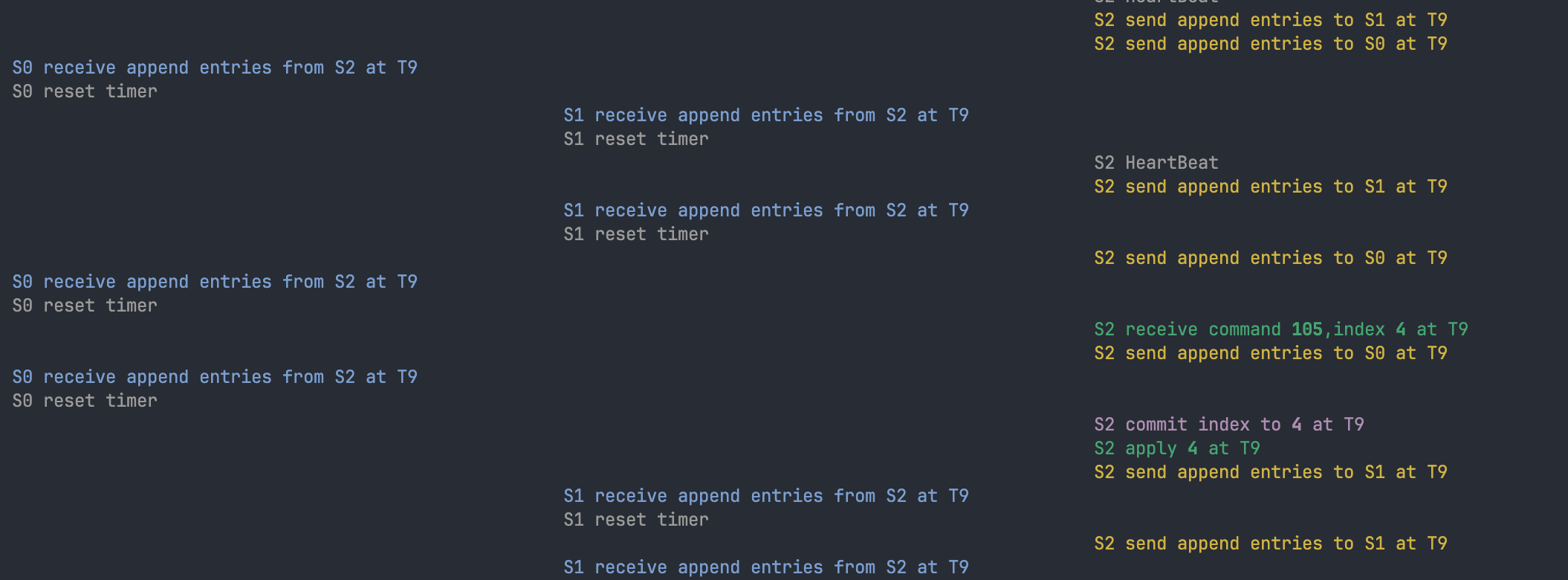
lab记录
lab 1——mapreduce
基本流程
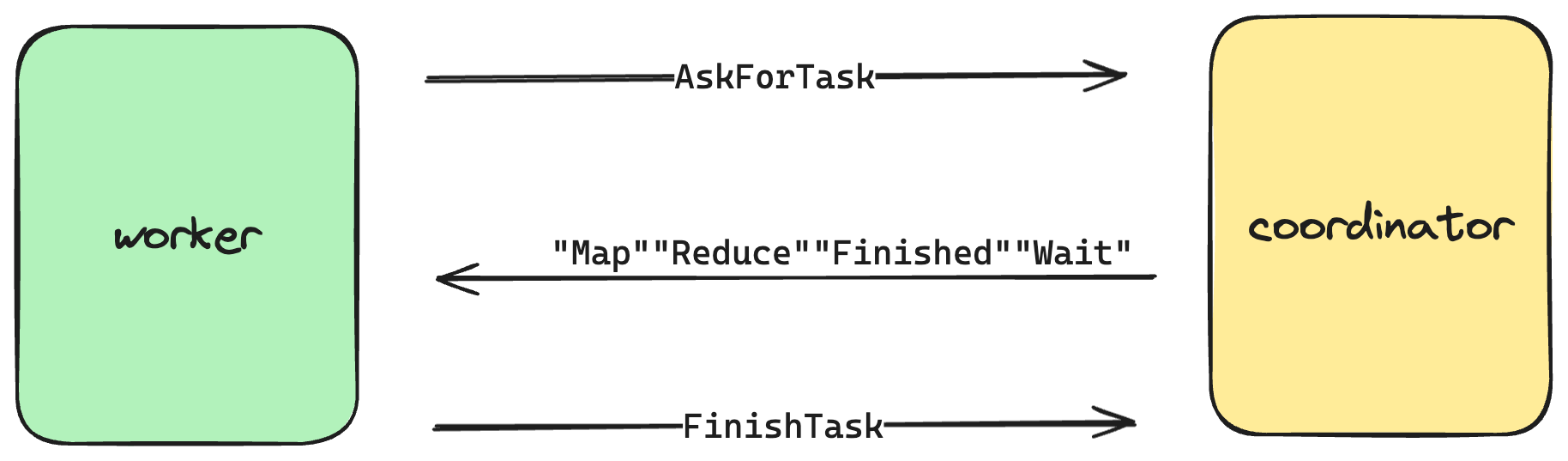
- worker会定期向coordinator发送rpc,询问自己当前需要做什么工作
- 在map阶段,coordinator将每个输入文件分配给一个worker,通知它进行map操作,每个worker完成之后发送rpc通知coordinator
- worker(map)对每个输入文件进行分词,每一个产生的k/v对根据hash值写入对应的中间文件中,命名规则为
mr-X-Y,X是map任务编号,y是reduce任务编号 - coordinator需要能够检测所有map任务是否都已完成
- map都完成后,reduce worker根据中间文件
mr-X-Y中的”Y”,在共享磁盘上找到相应的文件调用reduce函数
coordinator.go
type Coordinator struct {
input_files []string // 所有的输入文件
next_worker_id int // 下一个分配的worker id
next_map_input int // 下一个分配的map任务编号(一个输入文件对应一个map任务)
worker_infos map[int]workerInfo // 记录所有的worker的一些相关信息
finished_reduce_num int // 已完成reduce任务的数量
reduce_num int // 分配的reduce任务数量
next_reduce_id int // 下一个分配的reduce任务编号
mutex sync.Mutex // 用锁对共享数据结构进行保护
}
type workerInfo struct {
last_tast_time time.Time // 上次任务开始的时间
last_map_input_file string // map任务输入的文件
state string // "Map" "Reduce" "Wait" "Finished"
reduce_id int // reduce任务编号
map_id int // map任务编号
}
coordinator需要管理一些全局的信息,比如用worker_infos记录每一个worker的状态和任务相关信息
func (c *Coordinator) AskForTask(args *MapreduceArgs, reply *MapreduceReply) error {
c.mutex.Lock() // 用了一把大锁
if c.Done() {
// job已完成
reply.TaskType = "Finished"
c.mutex.Unlock()
return nil
}
if args.WorkerId == -1 {
// 初始worker ID为-1,coordinator需要分配一个新的ID
args.WorkerId = c.next_worker_id
c.next_worker_id++
}
if c.next_map_input < len(c.input_files) {
// map任务还没分配完,分配map任务给当前worker
reply.TaskType = "Map"
reply.WorkerId = args.WorkerId
reply.MapFile = c.input_files[c.next_map_input]
reply.ReduceNum = c.reduce_num
reply.MapId = c.next_map_input
c.worker_infos[args.WorkerId] = workerInfo{last_tast_time: time.Now(), last_map_input_file: reply.MapFile, state: "Map", map_id: c.next_map_input}
c.next_map_input++
c.mutex.Unlock()
return nil
}
// 检查是否所有的map任务都完成
var running_worker int
if !checkMapFinished(c, &running_worker) {
// 如果有map任务运行了10s还没结束,认为该worker宕机,重新分配这个map任务
if time.Since(c.worker_infos[running_worker].last_tast_time) > 10*time.Second {
reply.TaskType = "Map"
reply.WorkerId = args.WorkerId
reply.MapFile = c.worker_infos[running_worker].last_map_input_file
reply.ReduceNum = c.reduce_num
reply.MapId = c.worker_infos[running_worker].map_id
c.worker_infos[args.WorkerId] = workerInfo{last_tast_time: time.Now(), last_map_input_file: reply.MapFile, state: "Map", map_id: reply.MapId}
delete(c.worker_infos, running_worker)
} else {
// 有map任务没完成worker需要等待
reply.TaskType = "Wait"
reply.WorkerId = args.WorkerId
}
c.mutex.Unlock()
return nil
}
// 分配reduce任务
if c.next_reduce_id < c.reduce_num {
reply.TaskType = "Reduce"
reply.ReduceId = c.next_reduce_id
reply.WorkerId = args.WorkerId
reply.MapTaskNum = len(c.input_files)
c.next_reduce_id++
c.worker_infos[args.WorkerId] = workerInfo{last_tast_time: time.Now(), state: "Reduce", reduce_id: reply.ReduceId}
c.mutex.Unlock()
return nil
}
// 检查是否有reduce任务运行了10s还没结束
var crash_reduce_worker int
if checkReduceIfCrash(c, &crash_reduce_worker) {
reply.TaskType = "Reduce"
reply.ReduceId = c.worker_infos[crash_reduce_worker].reduce_id
reply.WorkerId = args.WorkerId
reply.MapTaskNum = len(c.input_files)
c.worker_infos[args.WorkerId] = workerInfo{last_tast_time: time.Now(), state: "Reduce", reduce_id: reply.ReduceId}
delete(c.worker_infos, crash_reduce_worker)
c.mutex.Unlock()
return nil
}
reply.TaskType = "Wait"
reply.WorkerId = args.WorkerId
log.Printf("wait for reduce task finishing\n")
c.mutex.Unlock()
return nil
}
worker.go
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
worker_id := -1
// ask coordinator for a task
for {
reply := MapreduceReply{}
CallAskForTask(worker_id, &reply)
worker_id = reply.WorkerId
log.Printf("worker %v get task %v\n", worker_id, reply.TaskType)
switch reply.TaskType {
case "Map":
map_worker(&reply, mapf, worker_id)
case "Wait":
time.Sleep(1 * time.Second) // 等待1s再发送请求
case "Reduce":
reduce_worker(&reply, reducef, worker_id)
case "Finished":
return
}
}
}
worker会循坏调用CallAskForTask函数,等待coordinator分配任务
遇到的一些问题
rpc的时候网络中断处理
- coordinator会记录每个worker上次分配任务(map或reduce)的时间,如果超过10秒worker还没结束任务,coordinator认为worker断开连接,将任务分配给新的worker
- worker使用rpc与coordinator建立连接的时候,如果通讯失败,最多可以重连3次
worker工作到一半宕机怎么办
worker先输出到一个临时文件,直到task结束时再原子地改名,防止其他worker读到写了一半就终止的文件
tmp, err = os.CreateTemp("./", "maptemp") // 在当前文件夹创建临时文件
tmp_append, err := os.OpenFile(tmp.Name(), os.O_APPEND|os.O_WRONLY, 0644) // 以append模式打开临时文件
os.Rename(tmp.Name(), fmt.Sprintf("mr-%v-%v", MapId, reduceid)) //改名
lab2
lab2A
guide中的一些要点
- 需要周期性地检查commitIndex > lastApplied,把log及时地apply到上层应用。同时,这个过程要小心并发,最好由一个线程来负责,避免提交的次序与log的次序不一致
- 区分nextIndex和matchIndex,nextIndex比较乐观,新上任的leader会把nextIndex设置为自己log的下一个index,如果appendEntry之后follower返回不匹配,再逐渐减小。而matchIndex储存的是确定的信息,初始化为-1,只有appendEntry成功返回之后才更新
遇到的一些问题
每个服务器需要字段记录自己是leader、follower或者candidate吗?如果不用,该怎么判断自身是否是leader
增加一个state字段表示目前的状态
当状态变更,而time.Sleep是个阻塞的函数,应该如何重置计时器
func (rf *Raft) ticker() {
for !rf.killed() {
time.Sleep(rf.heartBeatInterval)
rf.mu.Lock()
if rf.state == LEADER {
rf.leaderBroadCast()
}
if rf.state != LEADER && time.Now().After(rf.nextReElectionTime) {
if rf.state == FOLLOWER {
rf.state = CANDIDATE
}
go rf.startElection()
}
rf.mu.Unlock()
}
}
func (rf *Raft) resetTimer() {
ms := 230 + (rand.Int63() % 150)
rf.nextReElectionTime = time.Now().Add(time.Duration(ms) * time.Millisecond)
}
保存一个nextReElectionTime状态,表示下次计时器到期的时间。当1.自身成为candidate开始竞选 2.向别的候选人投票 3.收到来自leader的AppendEntry消息时,调用resetTimer刷新计时器到期时间
lab2B
自己刚开始写的时候,上层应用每次调用Start函数时,raft会向其他节点广播日志,就想到了一个问题。如果follower的log远远落后于leader,那么需要调用很多次AppendEntry,每次失败后减少对应的nextIndex,直到leader与follower匹配。如果上层应用几乎同时添加了2条命令,那么有大量的RPC都浪费在了回退nextIndex上。正巧看到了一篇博客,里面提到了为每一个peer分配一个专门的replicator来负责日志的同步,这样对于一个follower来说,一个时刻只会有一个go routine在运行,减少了冗余RPC的发送
func (rf *Raft) leaderBroadCast(isHeartBeat bool) {
rf.mu.RLock()
defer rf.mu.RUnlock()
for i := 0; i < len(rf.peers); i++ {
if i != rf.me {
if isHeartBeat {
go rf.replicateOneRound(i)
} else {
rf.replicatorCond[i].Signal()
}
}
}
}
func (rf *Raft) replicator(peer int) {
rf.replicatorCond[peer].L.Lock()
defer rf.replicatorCond[peer].L.Unlock()
for !rf.killed() {
// if there is no need to replicate entries for this peer, just release CPU and wait other goroutine's signal if service adds new Command
// if this peer needs replicating entries, this goroutine will call replicateOneRound(peer) multiple times until this peer catches up, and then wait
for !rf.needReplicating(peer) {
rf.replicatorCond[peer].Wait()
}
// maybe a pipeline mechanism is better to trade-off the memory usage and catch up time
rf.replicateOneRound(peer)
}
}
func (rf *Raft) needReplicating(peer int) bool {
rf.mu.RLock()
defer rf.mu.RUnlock()
return rf.state == LEADER && rf.matchIndex[peer] < rf.getLastLog().Index
}
每个replicator负责一个follower的日志同步,每当client通过Start函数传入了一个新的命令,leader会调用leaderBroadCast函数开始同步日志。leaderBroadCast使用条件变量通知replicator,这样无论client调用了多少次Start函数,对于每个follower,始终只有一个线程负责
至于为什么在leaderBroadCast中heartbeat消息不通过replicator发送,原因是因为replicator在被唤醒是会使用needReplicating函数检查follower的日志是否已经与leader同步了,如果已经同步,就继续等待。而heartbeat信息并不是为了同步,即使已经同步了仍要通知follower,所以才要把它单拎出来
func (rf *Raft) applier() {
rf.applyCond.L.Lock()
defer rf.applyCond.L.Unlock()
for !rf.killed() {
for !rf.canApply() {
rf.applyCond.Wait()
}
rf.mu.Lock()
for rf.commitIndex > rf.lastApplied {
Debug(dClient, "S%d apply %d at T%d\n", rf.me, rf.lastApplied+1, rf.currentTerm)
msg := ApplyMsg{CommandValid: true, Command: rf.log[rf.lastApplied+1].Command, CommandIndex: rf.lastApplied + 1}
rf.applyCh <- msg
rf.lastApplied++
}
rf.mu.Unlock()
}
}
func (rf *Raft) canApply() bool {
rf.mu.RLock()
defer rf.mu.RUnlock()
return rf.commitIndex > rf.lastApplied
}
applier在Make函数处使用go routine创建在后台运行,每当commitIndex改变,就唤醒条件变量applyCond
lab2C
遇到的一些问题
- 论文图8在讲什么
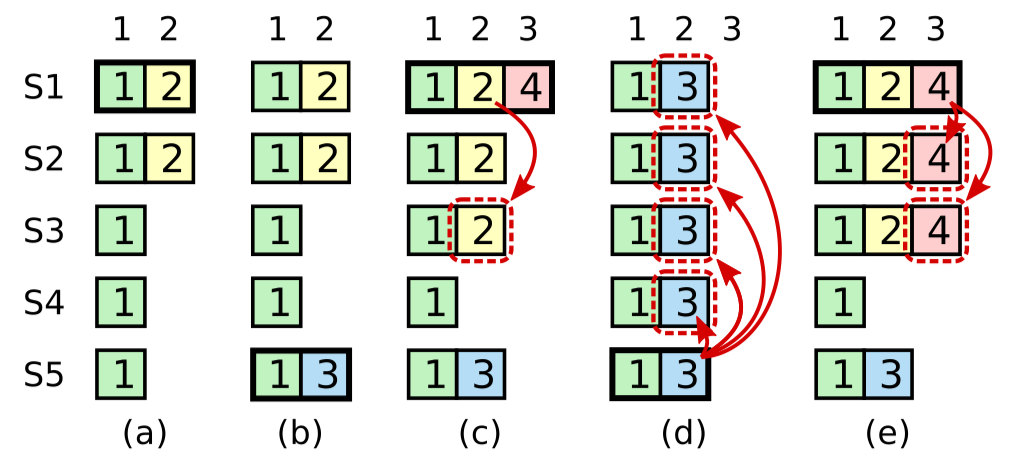
图8一开始没看明白它想表达的意思,后来在网上看了别人写的博客才知道。在(c)中,S1将2复制给了大部分节点,假设它现在将2 commit。在(d)中,S5拥有较新的term,被选举为leader,那么它会把3覆盖之前已经commit了的2,这就造成已经commit的log丢失了。 这个情况出现的本质原因是S5会认为S2和S3中index2的log是term为2的leader提交的,而自己当前的term大于2,所以可以安全地覆盖。
解决这个问题的方法论文中有提,那就是S1只能commit term与当前term一致的log,也就是说S1需要像(e)那样,通过commit 4来间接地commit 2.
这里还有一个问题,在(d)中,S5将3复制到了全部节点,此时仍然不能提交,因为S5是在S1宕机后被选举出来,它的term一定大于S1的term,至少为5,所以它不能提交log 3,直到当前term写入了新的log。那么问题就出现了,如果客户端在S5当选后客户端一直没有发送新的log,那么3这条log就一直commit不了,客户端会以为之前的报文丢失了然后重新发送一遍,S5 将新的这个 log 提交之后会顺便把 3 也提交,这样命令实际上执行了 2 次。论文中对此提出的解决方法是引入no-op日志,在leader当选后写入一条log,这条log与客户端发送的log唯一的不同在于存储的command指令为空,通过提交这条no-op日志,就可以把之前积攒的本地log及时地送入状态机。
但实际上 2c的测试样例并没有考虑到 no-op 这个 corner case,而且我尝试引入 no-op 后,由于 no-op 本身也会占用一个 index,反而 2B 中的测试样例通过不了了,所以我就暂时没管。
-
nextIndex回退的优化
如果不优化,如果一个节点落后leader太多,需要消耗大量的时间回退nextIndex,最后客户端没能在指定时间内接受 apply,测试样例就 fail 了
-
Another issue many had (often immediately after fixing the issue above), was that, upon receiving a heartbeat, they would truncate the follower’s log following
prevLogIndex, and then append any entries included in theAppendEntriesarguments. This is also not correct.follower 如何处理 leader 发送的entries[]
这个问题在student guide 中有提,一开始我的做法是将entries中所有的 log 拼接到 follower 的prevLogIndex之后,但其实这是有问题的,看下面这个例子
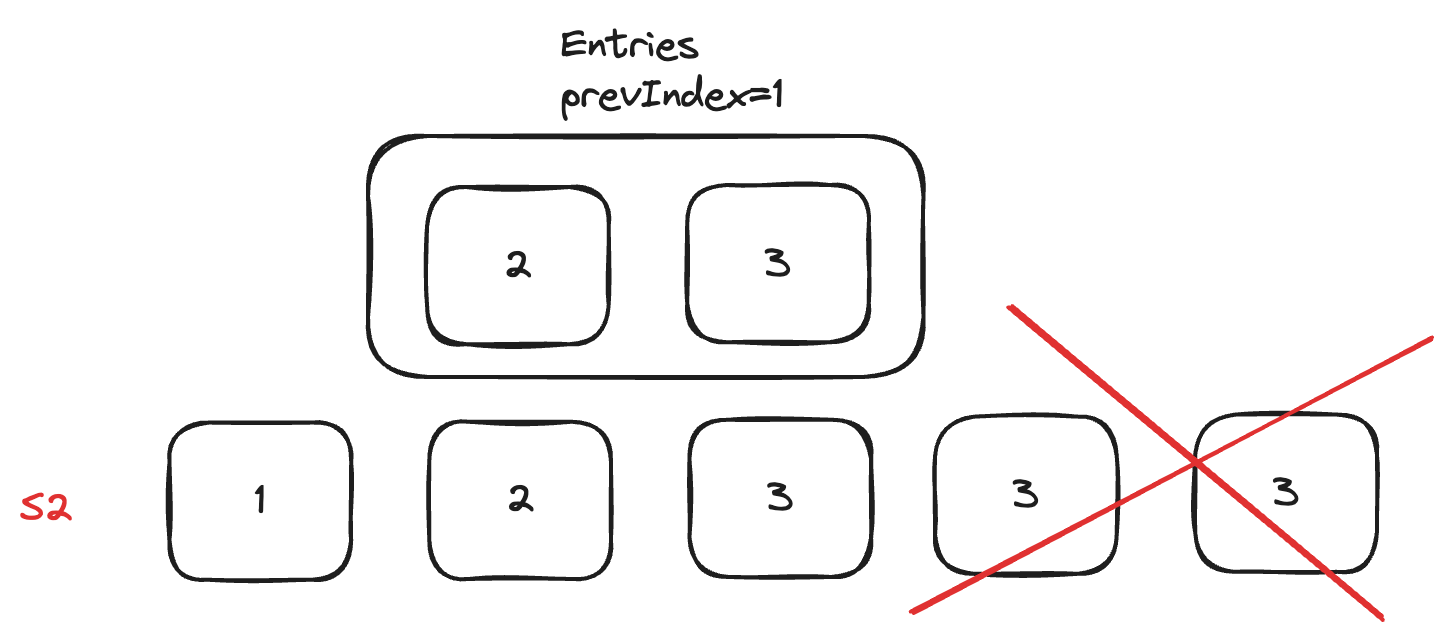
S2 的本地最后一个 log 的 term 为 5,但此时S2 收到了一个过期的 RPC AppendEntry 消息,如果像我一开始那样直接拼接到 prevIndex=1 后面,那么最后两个 log 就丢失了。
所以应该加一个判断,如果 AppendEntry 消息中的 Entries 在本地相应位置一模一样,那么就不作变动。否则才拼接到 prevIndex 之后
-
The
minin the final step (#5) ofAppendEntriesis necessary, and it needs to be computed with the index of the last new entry. It is not sufficient to simply have the function that applies things from your log betweenlastAppliedandcommitIndexstop when it reaches the end of your log. This is because you may have entries in your log that differ from the leader’s log after the entries that the leader sent you (which all match the ones in your log). Because #3 dictates that you only truncate your log if you have conflicting entries, those won’t be removed, and ifleaderCommitis beyond the entries the leader sent you, you may apply incorrect entries.follower 更新 commit 时index不应该超过 leader 发来的最后一个 log 的 index
这是因为leader 的 commitID 可能超过了发过来的 Entries 的长度
-
老是超时,无法达成共识
- 使用优化的nextIndex 方法
- 收到 AppendEntry 和 RequestVote 回复时要检查当前的状态是否分别为Leader 和 Candidate
- 一开始想当然,在收到 RequestVote 请求时如果比当前 term 大就重置计时器,这其实是不对的。试想网络中有个日志远远落后其他节点的candidate 一直发送 RequestVote 请求,其他节点发现他的日志并不up-to-date,拒绝投票给他,即使他的 term 比 currentTerm 更大。可是因为重置了计时器,自身一直不能超时参加竞选
-
如果出现单向故障怎么办,比如 leader 可以向 follower 发送RPC,但收不到回复
这种情况下 follower 会认为 leader 存活,不会超时而参加竞选,可是 leader 并不能收到RPC 的回复,使得客户端的命令一直 commit 不了。暂时并没想到好的解决方法
lab2D
遇到的一些问题
- 向客户端 apply 的 channel 可能阻塞
rf.mu.Lock()
for rf.commitIndex > rf.lastApplied {
Debug(dClient, "S%d apply %d at T%d\n", rf.me, rf.lastApplied+1, rf.currentTerm)
msg := ApplyMsg{CommandValid: true, Command: rf.getLogByIndex(rf.lastApplied + 1).Command, CommandIndex: rf.lastApplied + 1}
// if msg.Command == nil {
// msg.CommandValid = false
// }
rf.applyCh <- msg
rf.lastApplied++
Debug(dClient, "S%d current lastApplied is %d\n", rf.me, rf.lastApplied)
}
rf.mu.Unlock()
锁不应该包裹住rf.applyCh <- msg,因为如果客户端没有取出channel 中的数据,那么这个 channel 会阻塞
- 如果把所有的 log 都创建快照,log 的长度变成 0,如何与之前的逻辑保持一致性
如果快照中保存的状态的 index 到 13,那么rf.log = rf.log[13:],将index 为 13 的日志保留下来当作剩余 log 数组的第一个,从而避免 log 数组为空。为了防止可能的重放风险,设置rf.log[0].Command = nil,这样即使客户端重复的执行也不影响状态
- 切片的使用
src := []int{1, 2, 3, 4, 5}
dst := src[:2]
fmt.Println(dst) // [1 2]
src[0] = 9
fmt.Println(dst) // [9 2] dst 发生了变化
一开始leader 向 follower 发送 log 时使用的方法为类似**args.entries=rf.log[m:]**这样的语法,后来发现实际传送的内容会变化,其原因就是切片只是一种看待底层数组的“视角”,如果底层rf.log改变了,那么实际传送的 entries 也会改变。解决方法是发送信息时创建一个新的切片,发要传送的元素拷贝到新切片上。
dst := make([]int, 2)
copy(dst, src[:2])
另外一个要注意的就是收到 snapshot 后要清理 index 之前的日志,这一步也要创建一个新的切片,不能直接在原来的切片上改变大小,否则底层数组还是被引用的状态,无法被垃圾收集器清楚
newLog := make([]LogEntry, len(rf.log[index-rf.beginIndex:]))
copy(newLog, rf.log[index-rf.beginIndex:])
rf.log = newLog
- 为什么 lastAppied 不保存到磁盘?
我认为是为了简化设计,大不了将 log 重复 apply 给应用层,并没什么太大的影响。如果从效率的角度出发,也可以持久化,避免重传
- crash 后上层应用会自动读取快照吗?还是要再次 apply
客户端并不与持久层发生直接联系,所有状态的获取与保存均通过 raft 层,所以应该将快照 apply
